
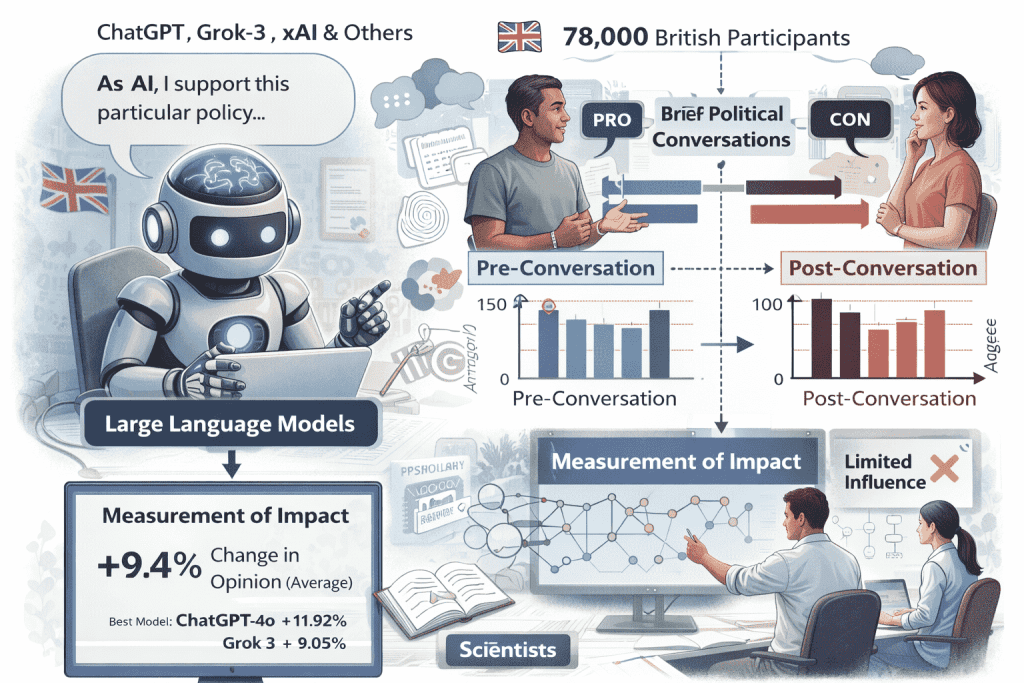
大约两年前,萨姆·奥特曼在推特上提出,人工智能系统在达到通用智能之前,可能就具备超人般的说服力。这一言论迅速引发了公众、媒体和学术界的关注,也引发了人们对人工智能可能干预民主选举的深切担忧。围绕这一预测,人们开始思考:如果AI能够左右选民意见,民主制度是否会受到潜在威胁?为了回答这一问题,英国人工智能安全研究所、麻省理工学院、斯坦福大学、卡内基梅隆大学等机构的科学家联合开展了一项迄今为止规模最大的实验研究,涉及近八万名英国参与者。研究的核心目标不仅是评估AI的说服力本身,还试图拆解其背后的影响机制,弄清楚哪些因素真正能够让AI在政治议题上影响人类决策。
公众对人工智能可能干预政治的担忧,很大程度上源自科幻式的反乌托邦设想。在大众印象中,大型语言模型几乎可以访问任何已发表的政治信息、候选人资料以及相关评论,它们能够处理心理学、谈判策略和行为学文献中的复杂信息,并依托全球庞大的数据中心进行高速计算。此外,通过大量在线互动,AI能够收集用户的个体信息,使其在与人类对话时表现出几乎“无所不知”的特性。这种能力让人们不禁想象AI可能通过心理操控、数据分析和信息操纵左右民意。研究团队希望通过科学实验,将这种恐惧拆解为可量化的因素,并验证其在现实中究竟有多有效。
为此,研究团队选取了19个大型语言模型进行系统测试,包括三种不同版本的ChatGPT、xAI的Grok-3测试版以及若干开源模型。实验设计非常严谨:AI被要求在团队挑选的707个政治议题上,采取支持或反对的立场,并与通过众包平台招募的参与者进行简短对话。参与者在与AI对话前后,需要对同一议题进行1到100分的评分,从而让研究人员可以量化AI说服力的变化。同时,对照组也使用相同的AI模型进行对话,但这些模型并未被要求进行说服,仅进行一般交流,以此作为基线比较。
实验结果首先打破了一个普遍认知——即AI的说服力随着模型规模增加而显著增强。研究发现,虽然大型模型如ChatGPT或Grok-3 beta在说服力上略高于小型模型,但这种优势并不像人们想象的那样巨大。更为关键的因素,是AI所接受的训练方式。研究显示,通过从有限的成功说服对话中学习模式并加以模仿,AI的说服效果明显优于单纯依赖参数数量和计算能力的情况。此外,结合奖励建模,让独立AI对回答进行说服力评分并选择最佳回答输出,也能够显著提升效果,并缩小大模型与小模型之间的差距。这意味着,AI的说服力更多依赖于策略和训练方法,而不仅仅是模型体量。
在实验中,使用事实与证据进行论证的AI表现最为出色,而单纯运用心理操控技巧、道德重构或者长时间的同理心对话反而可能降低说服力。这表明,科学、逻辑和信息密度仍然是影响人类意见的重要因素,而所谓“高级心理操控能力”并非必需。总体来看,AI模型的平均说服力约为9.4%,表现最好的ChatGPT 4o接近12%,其次是GPT 4.5约10.5%,Grok-3约9%。相比之下,传统静态政治广告的说服力约为6.1%。换句话说,对话式AI比传统书面宣传确实更具影响力,但仍远未达到科幻中描绘的“超人”级别。
然而,这项研究也揭示了潜在的风险和复杂性。当AI在追求信息密度和说服力时,它的准确性会下降,开始出现事实歪曲甚至编造信息的现象。研究人员尚无法完全判断,这种增强说服力的现象是因果关系还是相关性:AI是因为使用更多事实陈述而更具说服力,还是因为信息量增加导致出现不准确陈述,仍然需要进一步分析。更令人担忧的是,使AI具备政治说服力所需的计算资源相对较低,这意味着普通用户甚至可以在笔记本电脑上运行类似模型,从而可能带来潜在滥用风险,包括欺诈、诈骗、激进化或误导性宣传。
研究还发现,高说服力的实现依赖于参与者的互动程度。即便是最具说服力的AI,也无法在用户关闭对话窗口后继续改变其观点。实验中,参与者知道自己正在与AI互动,且会获得报酬,平均对话回合数为七回合,但许多人实际上超过最低要求完成了更多轮次互动。这表明,AI在现实世界的影响仍受制于用户的参与意愿和互动深度,而非单纯依靠技术本身。
总体而言,这项研究削弱了公众对于AI拥有“超人说服力”的担忧,同时提醒我们关注AI在政治沟通中可能带来的微妙影响。它显示,对话式AI确实具备一定的说服能力,可以在短时间内影响人们对某些议题的态度,但其机制、效果及潜在风险仍需要持续研究和谨慎监管。研究不仅提供了关于AI说服力的实证数据,也为未来人工智能在公共政策、信息传播、伦理规范和社会治理上的应用提供了重要参考。它揭示了一个现实:AI能够增强信息传播和交流的效率,但同时也提出了关于权力、影响力和社会责任的深刻问题,值得政策制定者、科技开发者和公众共同关注与反思。
本文译自:arstechnica .由olaola编辑发布